DeepSeek 本地部署:文件自动检测与知识库同步,含 OpenWebUI、Docker 及 Ollama 部署教程
在当今数字化时代,知识管理与高效检索成为提升个人和团队生产力的关键。如何将文件夹中的文件自动检测并同步到知识库中,同时利用强大的向量化模型进行高效检索,是许多技术爱好者和开发者关注的焦点。本文将带你深入了解如何通过 OpenWebUI 和 Ollama,结合 Docker 的强大容器化能力,实现一个本地化的、自动化的知识库同步与检索系统。
包含以下几个方面:
OpenWebUI 的美观以及强大:OpenWebUI 是一个开源的、用户友好的 AI 平台,支持多种大语言模型(LLM)运行器,包括 Ollama 和 OpenAI 兼容的 API。它不仅提供了一个直观的 Web 界面,还内置了 RAG 推理引擎,能够实现文档的向量化处理和检索。如果你有公网 IP 和内网穿透的相关知识储备,可以实现远程访问家里的 AI 终端。
Ollama 的向量化模型选择:Ollama 提供了多种模型用于文档向量化处理,例如 `bge-m3` 模型,能够高效地将文档转化为向量,从而实现精准检索。
Docker 的部署:Docker 的容器化技术可以极大地简化模型管理和服务集成。通过 Docker,我们可以快速部署 OpenWebUI 和 Ollama,并确保它们在隔离的环境中运行,避免依赖冲突。
自动化同步文件夹:通过配置和脚本,我们可以实现文件夹中文件的自动检测和同步,确保知识库始终保持最新。
接下来,我将详细展开每一步的部署过程,从安装 Docker 和 Ollama,到配置 OpenWebUI 的知识库,再到实现文件夹的自动化同步。无论你是技术新手还是资深开发者,本文都将为你提供清晰的指引,帮助你快速搭建一个高效、安全且易于管理的本地知识库系统。
首先安装 Ollama 和 Docker: 进入二者的官网:
Ollama官网
Docker官网
下载并且安装 Ollama 和 Docker(如果能科学上网会比较节省时间)。
Ollama:
这里以 Windows 平台为例子:安装 for Windows 版本,下载完成后直接安装,但需要注意它默认安装到 C 盘且不能更改,如需迁移到其他盘可以自行搜索其他教程(涉及到相关的环境和路径问题)或者等我继续出后续教程。
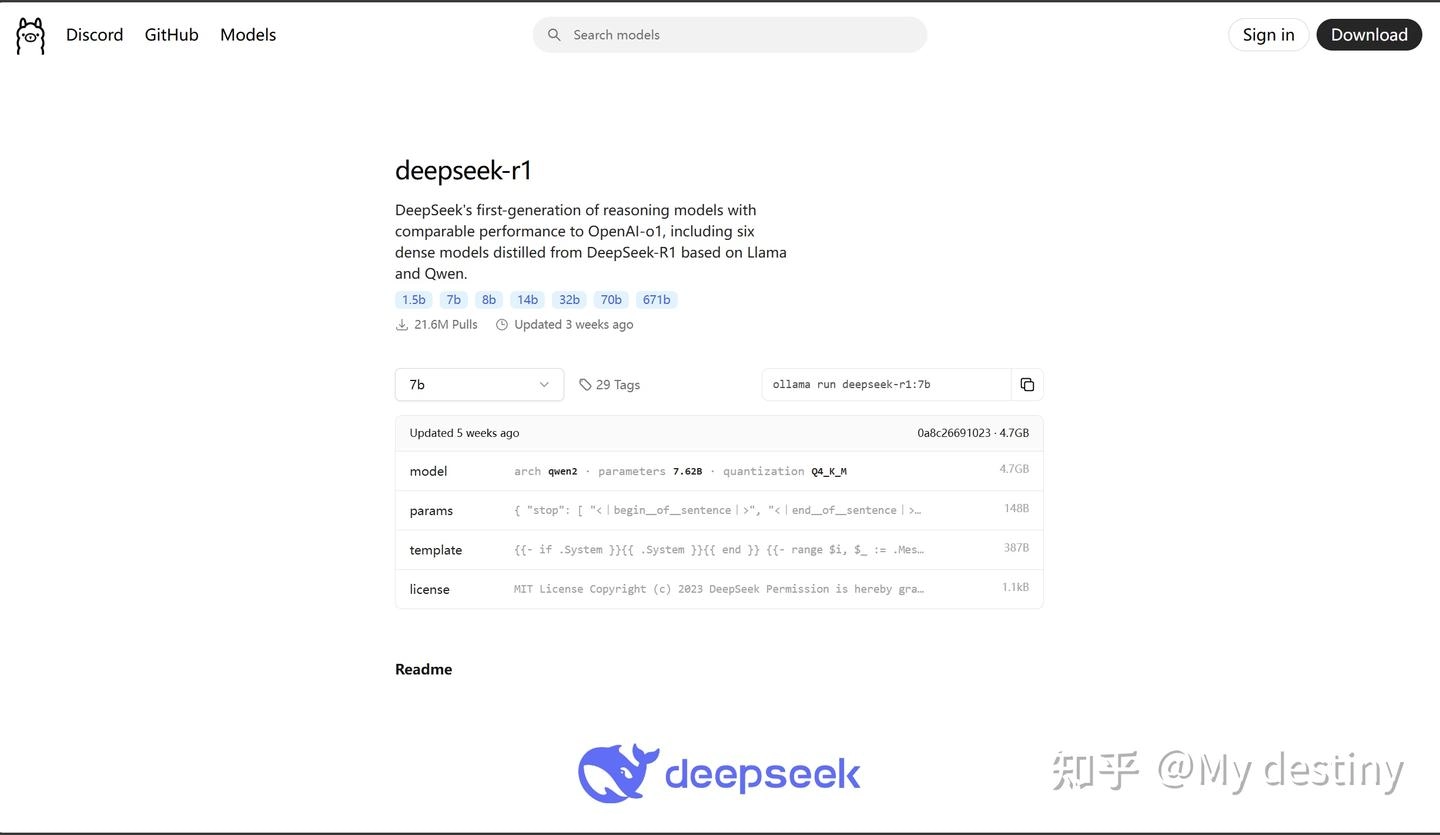
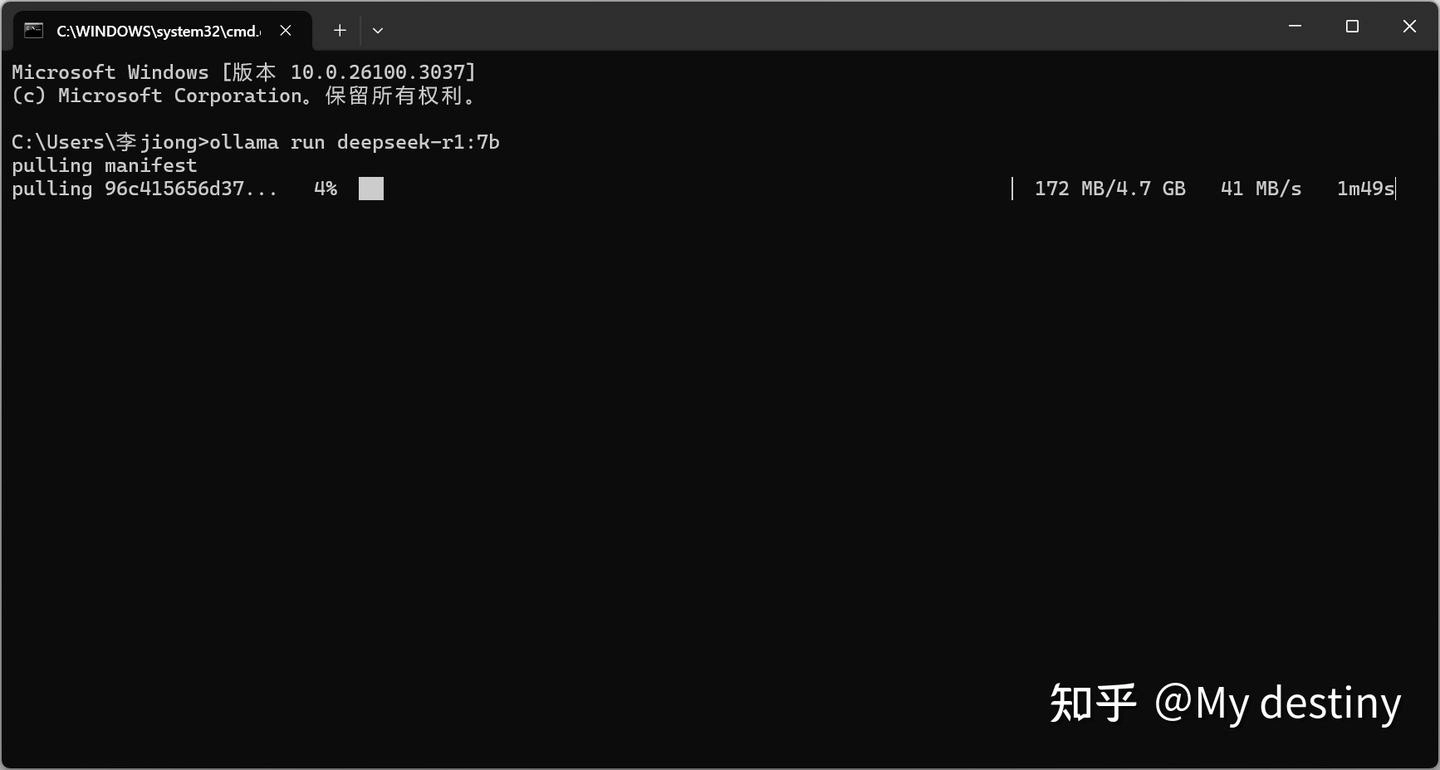
安装完成后回到它的官网点击左上角的 Models,选择需要的 LLM 模型并且复制下载命令,这里我选择的是 deepseek-r1-7b 版本:
命令就是ollama run那一串,点击后面的复制即可
然后同时按 win+R,在弹出的窗口输入 cmd 打开终端:
将刚刚复制的命令粘贴进去并且回车:
如果下载更大的模型遇到中途网速怎么都跑不起来可以 Ctrl+C 暂停后按上档并且回车重启下载,一般会好一些
下载完成后可以直接在终端进行对话(如果需要的话,下一次在终端启动可以继续使用上面那个相同的命令激活。)
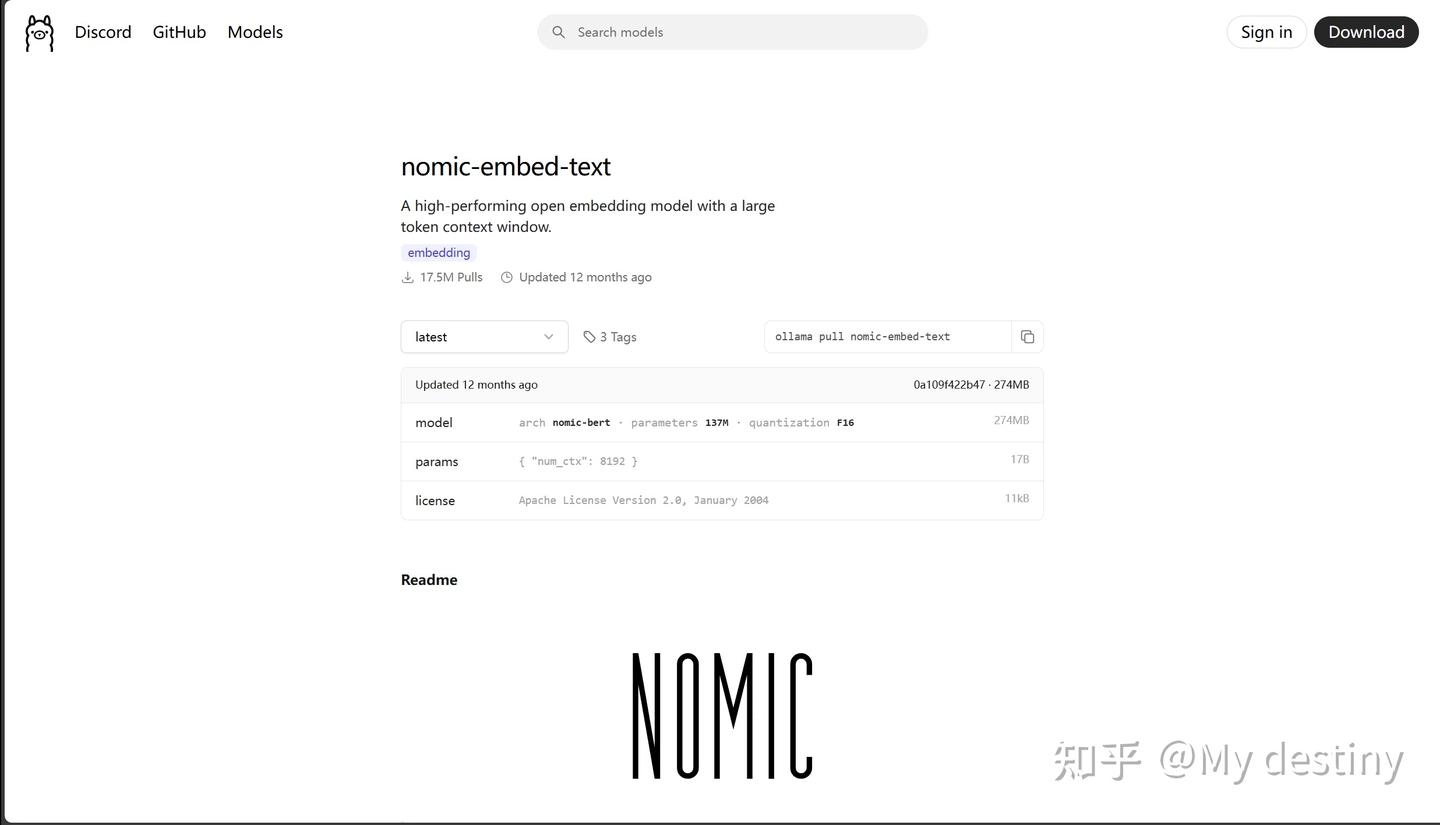
此时还需要在 Ollama 安装 Ebedding 模型(经过和默认模型以及国内先进的模型对比我选择了以下模型):
该模型的拉取和上文 Deepseek 的拉取一致。
拉取完成后可用在终端敲入以下代码来查看已经下载的模型:
Docker 的安装(安装过程中会让你选择是否用 wsl2 取代 Hyper-v,如果你的电脑有正确版本的 wsl2 就勾选,如果没有就不勾,如何查看有没有自带 wsl2 呢?在上文的终端处输入:wsl –list –verbose 点击回车,如果出现 wsl –set-default-version 2 说明 wsl2 已经存在,否则就继续看下文):
此处有需要注意的地方,如果你的系统是 Windows 家庭版或者学生版 Hyper-v 虚拟机默认是不存在或者没法激活的。需自行设置:详见我的另一篇知乎上的回答,比较简短。链接在此
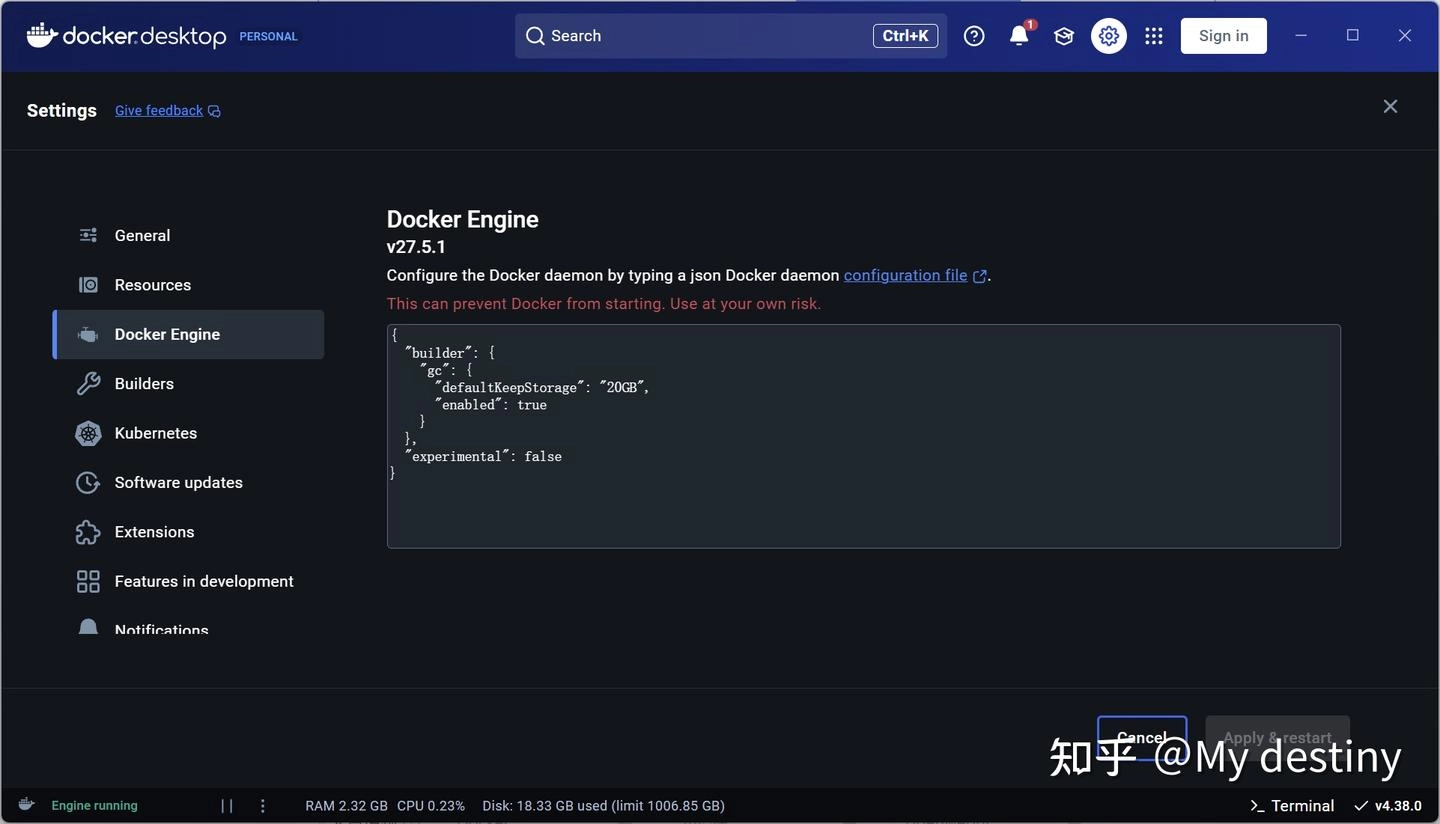
Docker 安装完成后有部分型号电脑会要求重启,重启后 Docker 应该会自启动,如果电脑无法进行科学上网,进入 Setting–Docker engine,将以下代码替换进入框内。
1 2 3 { "registry-mirrors": ["https://docker.mirrors.ustc.edu.cn"] }
Openweb UI 的配置(以下分为两种情况,一种为科学上网可用,一种为无法连接境外互联网可用):
无法连接境外互联网:继续上文的步骤,在终端中输入以下命令来拉取清华的镜像源:
1 docker pull ghcr.io/open-webui/open-webui:main
在镜像源拉取成功后输入以下命令:
不需要使用 NVIDIA Cuda 加速:
1 docker run -d -p 3000:8080 --add-host=host.docker.internal:host-gateway -v open-webui:/app/backend/data --name open-webui --restart always ghcr.io/open-webui/open-webui:main
需要使用 NVIDIA Cuda 加速(确保 NVIDIA 显卡驱动更新到最新):
1 docker run -d -p 3000:8080 --gpus all --add-host=host.docker.internal:host-gateway -v open-webui:/app/backend/data --name open-webui --restart always ghcr.io/open-webui/open-webui:cuda
2.科学上网可用(不需要更改 Docker engine 设置):访问 OpenWeb UI 官网
复制官网提供的 Docker 命令:
不需要使用 NVIDIA Cuda 加速:
1 docker run -d -p 3000:8080 --add-host=host.docker.internal:host-gateway -v open-webui:/app/backend/data --name open-webui --restart always ghcr.io/open-webui/open-webui:main
需要使用 NVIDIA Cuda 加速(确保 NVIDIA 显卡驱动更新到最新):
1 docker run -d -p 3000:8080 --gpus all --add-host=host.docker.internal:host-gateway -v open-webui:/app/backend/data --name open-webui --restart always ghcr.io/open-webui/open-webui:cuda
程序拉取完成后进入 Docker 应该可以看到如下画面:
点击 Ports 下的端口号,将会跳转浏览器并且启动 OpenWeb UI 的界面。初次登陆会让你注册用户,第一个注册的用户将会成为权限最大的管理员,账号密码等信息都是存在本地的不用担心信息泄露。
如果此时链接不上 Ollama 内的模型,可能是 Ollama 的本地 API 出现问题,一般这个问题会出现在使用国内镜像源拉取的 OpenWeb UI 上,进入设置-管理员设置-外部链接,将 Ollama API 切换成以下代码:
1 http://host.docker.internal:11434
现在应该可以和你的模型进行正常的对话了,记住将 LLM 模型(此处为 Deepseek)设为默认,对 Ebedding 模型说话会报错!
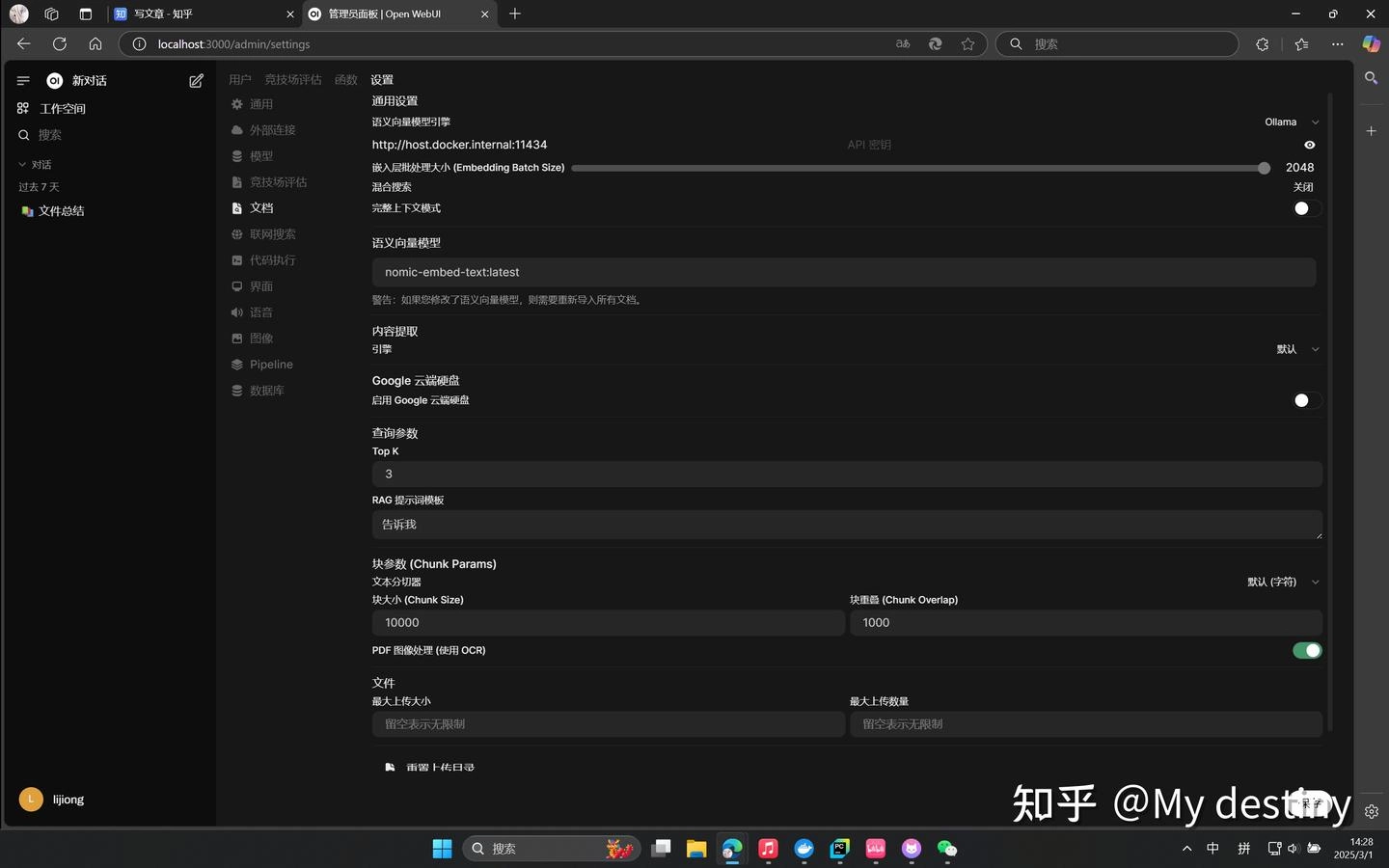
调整 Web UI:接下来配置知识库所需的文件的处理细节:依旧是在设置-管理员设置-文档,将语义向量模型引擎切换成 Ollama 并且将语义向量模型设置为 nomic-embed-text:latest 其他设置可以按照图里面的需求调整,如果你有其他需求也可以自行调整,调整完毕需要点击保存:
知识库:工作空间 - 知识库 - 创建知识库,根据你的需求来创建知识库(可以选择对全部用户开放还是创建私人知识库,最高级管理员可以看见所有用户创建的知识库不管是 Public/Private)。
现在需要获取自己 Web UI 的 API key,进入设置 - 账户 - API 密钥 - 启用 API 密钥,复制 API 密钥,不要用 JWT 令牌:
获取知识库的 ID,每一个知识库都有自己独立的 ID:
进入一个知识库,在导航栏上最后一串数字字母混合物就是这个知识库的 ID:
自动监视并且同步目标文件夹内的文件进入指定知识库: 以下是重点!!!
OpenWeb UI 只能支持 .docx .csv .pdf .txt 文件老版本的 .doc .xlsx .xls 文件需要转化后才能上传,如果需要这个自动监控并且转换的脚本可以去我的 GitHub 上拿:链接在此
先放上我的代码可以从 GitHub 上拉取也可以直接复制到自己的 IDE 里面使用或者用 pyinstaller 封装成 .exe 食用😋(记得安装所有的依赖和库噢),如果需要看稍微详细一点的讲解可以继续往下滑😘链接在此
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 142 143 144 145 146 147 148 149 150 151 152 153 154 155 156 157 158 159 160 161 162 163 164 165 166 167 168 import os import time import hashlib import requests from watchdog.observers import Observer from watchdog.events import FileSystemEventHandler # API 和全局配置 API_BASE_URL = 'http://localhost:3000/api/v1/' TOKEN = "sk-523ecf21baf04d66aba4dde8e9981295" # 替换为你的授权令牌 # 文件夹与知识库的映射关系,前面是文件夹路径,后面是知识库ID,每一个知识库都有自己的ID FOLDER_KNOWLEDGE_MAP = { r"E:\transform\total": "24010f9e-3fbb-463b-b179-cfab81fdd70e", r"E:\transform\main": "c0ef0ee8-6ac2-46f0-9ee3-2e606024c4ea", r"E:\transform\project": "ac8b155d-c24b-433b-80e4-8b6e7053ff0c", r"E:\transform\base": "e1f06477-9442-4029-b905-fc6429d13da6", r"E:\transform\file": "6cca427c-dad2-40d4-9b61-1c54e739cd81", r"E:\transform\work": "a6fa4855-f2c7-4926-87b0-6b3abc7e8fca" } # 文件存储状态(保存已上传文件的信息,避免重复上传) uploaded_files = {} # 指定哈希文件的保存路径 PERSISTENCE_FILE = r"E:\transform\hashes.txt" # 替换为你的哈希文件保存路径 # 日志函数 def log(message, level="INFO"): print(f"[{level}] {message}") # 确保哈希文件存在 def ensure_persistence_file(): if not os.path.exists(PERSISTENCE_FILE): log(f"Hash file does not exist. Creating a new one at {PERSISTENCE_FILE}") open(PERSISTENCE_FILE, "w").close() # 加载已上传文件的哈希值 def load_uploaded_files(): log(f"Loading uploaded files from {PERSISTENCE_FILE}...") try: with open(PERSISTENCE_FILE, "r") as f: for line in f: line = line.strip() if line: try: file_path, checksum = line.split("|") uploaded_files[file_path] = checksum log(f"Loaded {file_path} with checksum {checksum}", level="DEBUG") except ValueError: log(f"Skipping invalid line in hash file: {line}", level="WARNING") except FileNotFoundError: log(f"Hash file {PERSISTENCE_FILE} not found. Starting with an empty hash list.", level="WARNING") # 保存已上传文件的哈希值 def save_uploaded_files(): log(f"Saving uploaded files to {PERSISTENCE_FILE}...") try: with open(PERSISTENCE_FILE, "w") as f: for file_path, checksum in uploaded_files.items(): f.write(f"{file_path}|{checksum}\n") log("Successfully saved uploaded files.") except Exception as e: log(f"Failed to save uploaded files: {e}", level="ERROR") # 上传文件到知识库 def upload_file(file_path, knowledge_id): headers = { 'Authorization': f'Bearer {TOKEN}', 'Accept': 'application/json' } log(f"Uploading {file_path} to knowledge {knowledge_id}") try: with open(file_path, 'rb') as file: checksum = hashlib.sha256(file.read()).hexdigest() if file_path in uploaded_files and uploaded_files[file_path] == checksum: log(f"File {file_path} has already been uploaded. Skipping.", level="DEBUG") return with open(file_path, 'rb') as file: response = requests.post( f'{API_BASE_URL}files/', headers=headers, files={'file': file}, timeout=200 ) if response.status_code == 200: file_id = response.json().get('id') add_file_to_knowledge(file_id, knowledge_id) uploaded_files[file_path] = checksum log(f"Successfully uploaded {file_path}") else: log(f"Error uploading {file_path}: {response.status_code} - {response.text}", level="ERROR") except requests.exceptions.RequestException as e: log(f"Failed to upload {file_path}: {e}", level="ERROR") # 将文件添加到知识库 def add_file_to_knowledge(file_id, knowledge_id): headers = { 'Authorization': f'Bearer {TOKEN}', 'Content-Type': 'application/json' } data = {'file_id': file_id} response = requests.post( f'{API_BASE_URL}knowledge/{knowledge_id}/file/add', headers=headers, json=data ) if response.status_code != 200: log(f"Error adding file {file_id} to knowledge {knowledge_id}: {response.status_code} - {response.text}", level="ERROR") # 文件系统事件处理器 class SyncHandler(FileSystemEventHandler): def __init__(self, source_folder, knowledge_id): self.source_folder = source_folder self.knowledge_id = knowledge_id def on_created(self, event): if not event.is_directory: file_path = event.src_path file_name = os.path.basename(file_path) if (os.path.exists(file_path) and os.path.getsize(file_path) > 0 and not file_name.startswith('~$') and not file_name.endswith('.tmp')): upload_file(file_path, self.knowledge_id) log(f"Detected new file: {file_path}") def on_modified(self, event): if not event.is_directory: file_path = event.src_path file_name = os.path.basename(file_path) if (os.path.exists(file_path) and os.path.getsize(file_path) > 0 and not file_name.startswith('~$') and not file_name.endswith('.tmp')): upload_file(file_path, self.knowledge_id) log(f"Detected modified file: {file_path}") def on_deleted(self, event): if not event.is_directory: file_path = event.src_path if file_path in uploaded_files: del uploaded_files[file_path] log(f"Deleted file {file_path} removed from uploaded_files list.") # 程序启动时进行增量同步 def initial_sync(folder, knowledge_id): log(f"Performing initial sync for folder {folder} with knowledge {knowledge_id}") for root, _, files in os.walk(folder): for file in files: file_path = os.path.join(root, file) if (os.path.exists(file_path) and os.path.getsize(file_path) > 0 and not file.startswith('~$') and not file.endswith('.tmp')): upload_file(file_path, knowledge_id) # 主函数 def main(): log("Starting file synchronization...") ensure_persistence_file() load_uploaded_files() observers = [] for folder, knowledge_id in FOLDER_KNOWLEDGE_MAP.items(): # Perform initial sync to handle any changes that occurred while the program was not running initial_sync(folder, knowledge_id) log(f"Setting up observer for folder {folder} with knowledge {knowledge_id}") observer = Observer() handler = SyncHandler(folder, knowledge_id) observer.schedule(handler, folder, recursive=True) observer.start() observers.append(observer) try: while True: time.sleep(1) except KeyboardInterrupt: log("Stopping synchronization...") save_uploaded_files() for observer in observers: observer.stop() for observer in observers: observer.join() if __name__ == "__main__": main()
好,下面来讲解一下代码:
这段代码实现了一个文件同步工具,用于监控指定文件夹中的文件变化,并将新增或修改的文件上传到远程知识库(通过API接口)。它利用了 watchdog 库来监控文件系统事件,并通过哈希值(SHA-256)来避免重复上传文件。同时,它还支持增量同步,确保程序启动时能够处理之前未同步的文件。
1. 导入模块:
1 2 3 4 5 6 import os import time import hashlib import requests from watchdog.observers import Observer from watchdog.events import FileSystemEventHandler
导入了实现文件监控、文件操作、网络请求和哈希计算所需的模块。
2. 全局配置:
1 2 3 4 5 6 7 API_BASE_URL = 'http://localhost:3000/api/v1/' TOKEN = "sk-523ecf21baf04d66aba4dde8e9981295" # 替换为你的授权令牌 FOLDER_KNOWLEDGE_MAP = { r"E:\transform\total": "24010f9e-3fbb-463b-b179-cfab81fdd70e", r"E:\transform\main": "c0ef0ee8-6ac2-46f0-9ee3-2e606024c4ea", ... }
API_BASE_URL:定义了远程 API 的基地址,用于上传文件和管理知识库。
TOKEN:用于认证的 API 令牌,确保上传操作的合法性。
FOLDER_KNOWLEDGE_MAP:将本地文件夹与远程知识库 ID 进行映射,确保文件上传到正确的知识库。
3. 日志函数:
1 2 def log(message, level="INFO"): print(f"[{level}] {message}")
提供了一个简单的日志记录功能,用于输出程序运行过程中的信息或错误。
默认日志级别为 INFO,可通过 level 参数指定其他级别(如 ERROR 或 DEBUG)。
4. 哈希文件管理:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 def ensure_persistence_file(): if not os.path.exists(PERSISTENCE_FILE): log(f"Hash file does not exist. Creating a new one at {PERSISTENCE_FILE}") open(PERSISTENCE_FILE, "w").close() def load_uploaded_files(): log(f"Loading uploaded files from {PERSISTENCE_FILE}...") try: with open(PERSISTENCE_FILE, "r") as f: for line in f: line = line.strip() if line: try: file_path, checksum = line.split("|") uploaded_files[file_path] = checksum except ValueError: log(f"Skipping invalid line in hash file: {line}", level="WARNING") except FileNotFoundError: log(f"Hash file {PERSISTENCE_FILE} not found. Starting with an empty hash list.", level="WARNING")
ensure_persistence_file:确保哈希文件存在,如果不存在则创建一个空文件。
load_uploaded_files:从哈希文件中加载已上传文件的路径和对应的 SHA-256 哈希值,用于后续避免重复上传。
5. 文件上传:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 def upload_file(file_path, knowledge_id): headers = { 'Authorization': f'Bearer {TOKEN}', 'Accept': 'application/json' } log(f"Uploading {file_path} to knowledge {knowledge_id}") try: with open(file_path, 'rb') as file: checksum = hashlib.sha256(file.read()).hexdigest() if file_path in uploaded_files and uploaded_files[file_path] == checksum: log(f"File {file_path} has already been uploaded. Skipping.", level="DEBUG") return with open(file_path, 'rb') as file: response = requests.post( f'{API_BASE_URL}files/', headers=headers, files={'file': file}, timeout=200 ) if response.status_code == 200: file_id = response.json().get('id') add_file_to_knowledge(file_id, knowledge_id) uploaded_files[file_path] = checksum log(f"Successfully uploaded {file_path}") else: log(f"Error uploading {file_path}: {response.status_code} - {response.text}", level="ERROR") except requests.exceptions.RequestException as e: log(f"Failed to upload {file_path}: {e}", level="ERROR")
计算文件的 SHA-256 哈希值,检查是否已上传过。
如果文件未上传,则通过 requests.post将文件上传到远程API。
如果上传成功,将文件ID与知识库关联,并将文件路径和哈希值记录到 uploaded_files 字典中。
6. 文件系统事件处理器:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 class SyncHandler(FileSystemEventHandler): def __init__(self, source_folder, knowledge_id): self.source_folder = source_folder self.knowledge_id = knowledge_id def on_created(self, event): if not event.is_directory: file_path = event.src_path if os.path.exists(file_path) and os.path.getsize(file_path) > 0: upload_file(file_path, self.knowledge_id) log(f"Detected new file: {file_path}") def on_modified(self, event): if not event.is_directory: file_path = event.src_path if os.path.exists(file_path) and os.path.getsize(file_path) > 0: upload_file(file_path, self.knowledge_id) log(f"Detected modified file: {file_path}") def on_deleted(self, event): if not event.is_directory: file_path = event.src_path if file_path in uploaded_files: del uploaded_files[file_path] log(f"Deleted file {file_path} removed from uploaded_files list.")
SyncHandler继承自 FileSystemEventHandler,用于处理文件系统事件。
on_created:当文件被创建时,调用 upload_file 上传文件。
on_modified:当文件被修改时,重新上传文件。
on_deleted:当文件被删除时,从 uploaded_files 字典中移除该文件的记录。
7. 启动时增量同步:
1 2 3 4 5 6 7 def initial_sync(folder, knowledge_id): log(f"Performing initial sync for folder {folder} with knowledge {knowledge_id}") for root, _, files in os.walk(folder): for file in files: file_path = os.path.join(root, file) if os.path.exists(file_path) and os.path.getsize(file_path) > 0: upload_file(file_path, knowledge_id)
在程序启动时,对指定文件夹进行增量同步。
遍历文件夹中的所有文件,并调用 upload_file 上传文件,确保文件夹中的文件与远程知识库保持一致。
8. 主函数:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 def main(): log("Starting file synchronization...") ensure_persistence_file() load_uploaded_files() observers = [] for folder, knowledge_id in FOLDER_KNOWLEDGE_MAP.items(): initial_sync(folder, knowledge_id) observer = Observer() handler = SyncHandler(folder, knowledge_id) observer.schedule(handler, folder, recursive=True) observer.start() observers.append(observer) try: while True: time.sleep(1) except KeyboardInterrupt: log("Stopping synchronization...") save_uploaded_files() for observer in observers: observer.stop() for observer in observers: observer.join()
程序入口,负责初始化和启动文件同步功能。
调用 ensure_persistence_file 和 load_uploaded_files 加载哈希文件。
对每个文件夹启动一个 Observer,并为其分配一个 SyncHandler。
程序运行时,主线程进入循环,等待用户中断(KeyboardInterrupt)。
程序退出时,保存哈希文件并停止所有 Observer。
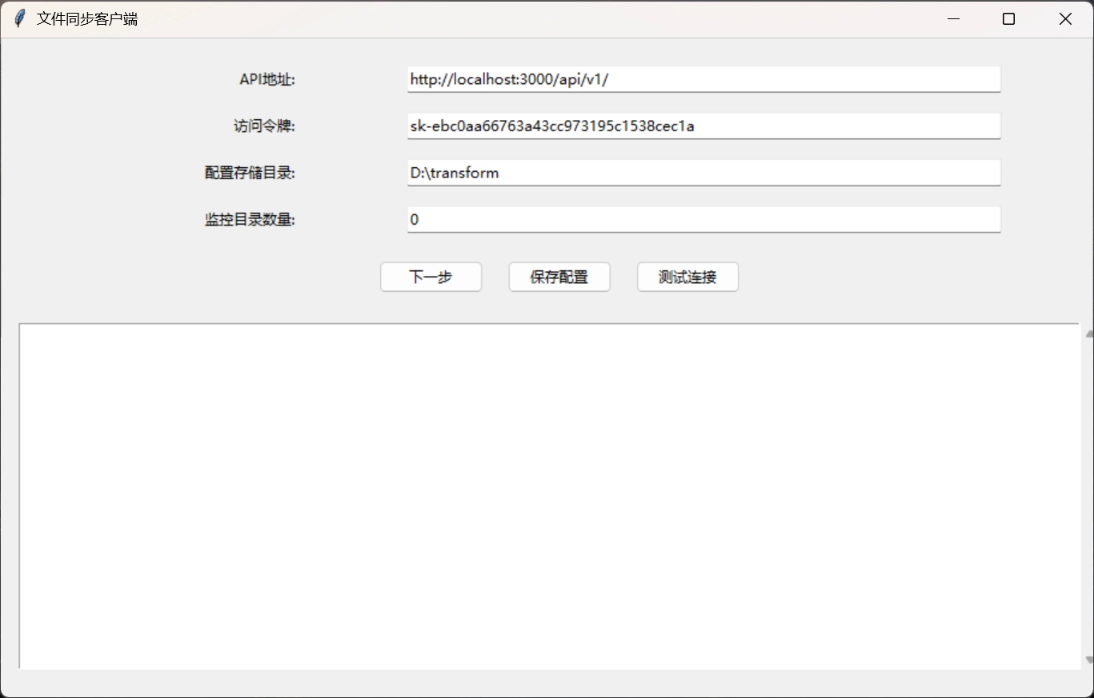
以上就是代码的讲解啦,文章到这里就差不多结束了,后续还有新的发现和功能实现我将会持续更新😋 经过几次小迭代,转化功能和同步功能已经被我整合到一起去了,并且封装成exe文件,压缩包还是在之前Github的链接上,请按照以下步骤来进行同步和上传功能的配置:
2.将另一个名为Sync-OpenWebUI的exe文件添加到Windows任务计划程序中,设置为开机延时2min启动(等待Open web UI启动以防出现bug),重启电脑查看任务管理器中这个程序进程是否正常,如果正常文件应该正常被转化和上传到知识库中。转化后的文件存在你设置的配置文件储存地址。中文文件夹被重命名为拼音简写。
如果有在Linux上部署需求的朋友,可以移步我的另一篇文章:Linux下进行
也欢迎关注我的知乎账号:点击此处跳转
转载记得标明出处噢!😘😋