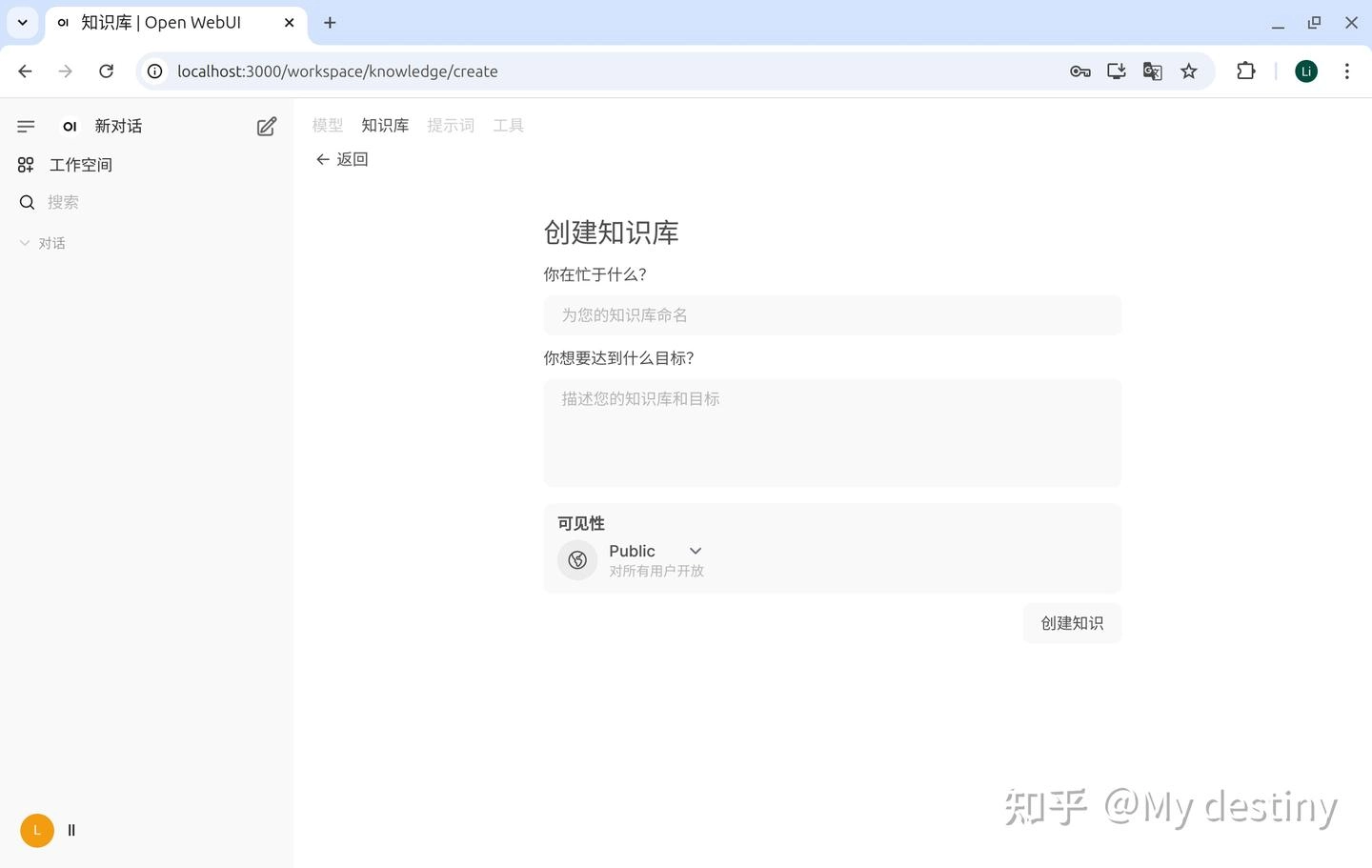
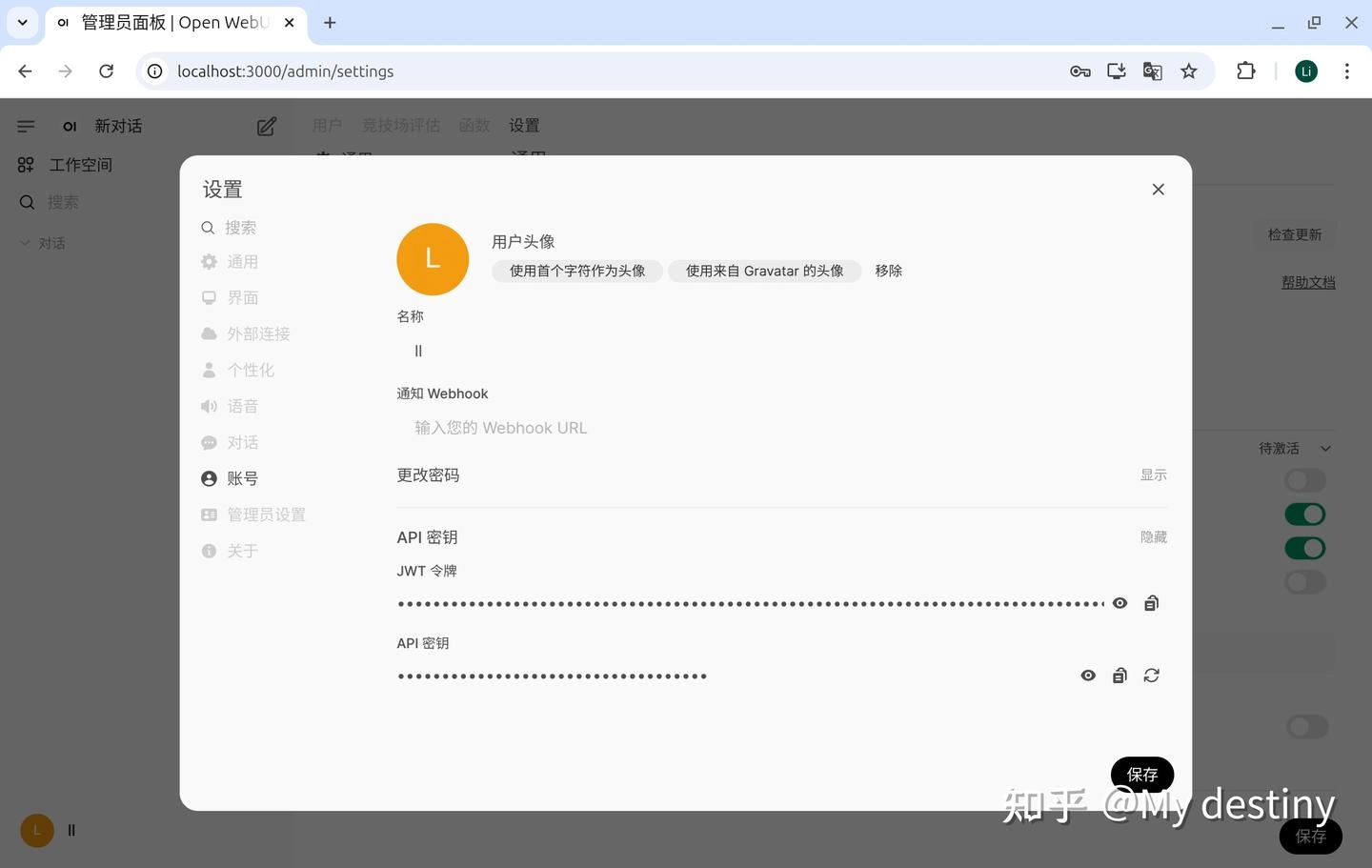
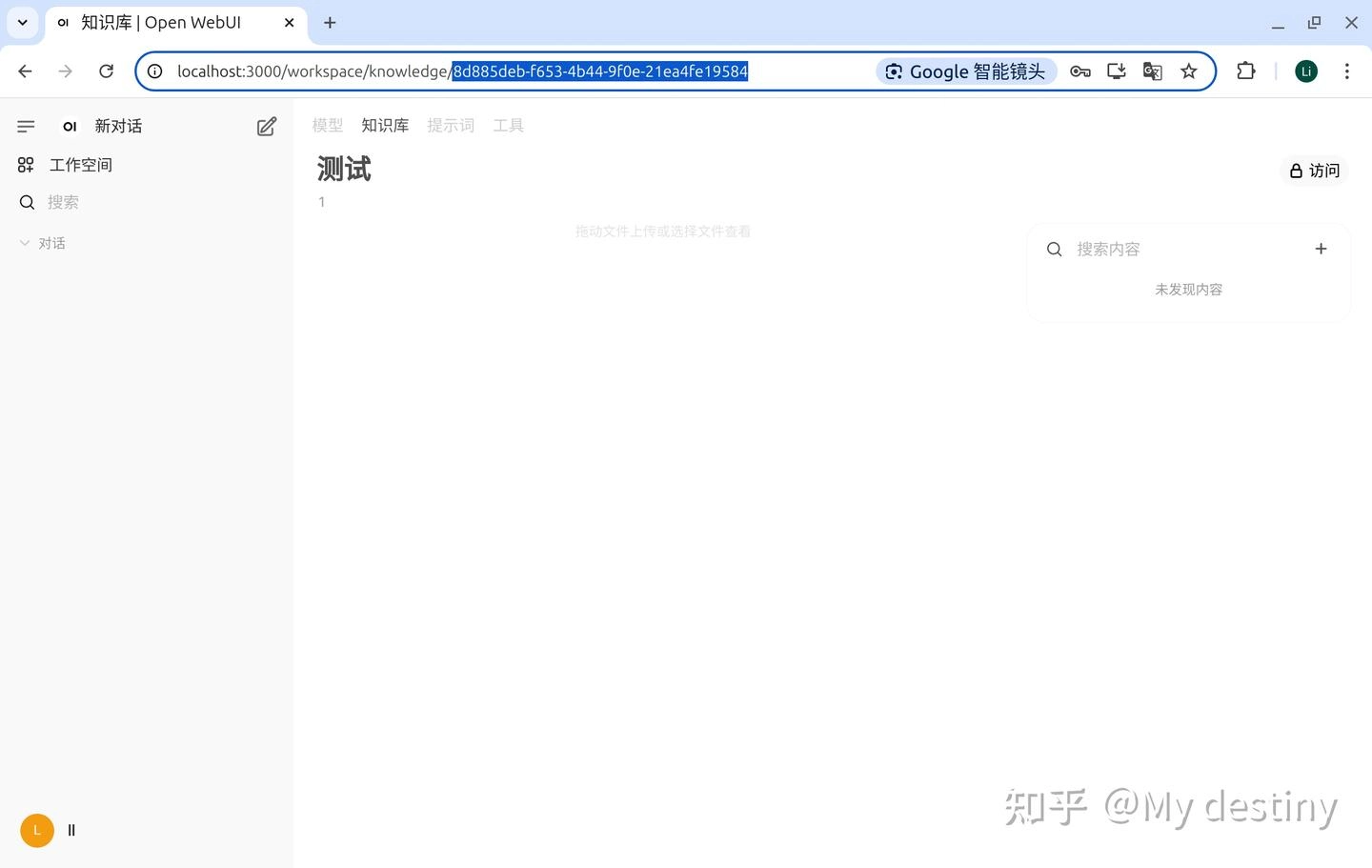
import os import time import hashlib import requests from watchdog.observers import Observer from watchdog.events import FileSystemEventHandler # API 和全局配置 API_BASE_URL = 'http://localhost:3000/api/v1/' TOKEN = "sk-7ff02c364c57478ab3dcc062eaaf4fe6" # 替换为你的授权令牌 # 文件夹与知识库的映射关系,前面是文件夹路径,后面是知识库ID,每一个知识库都有自己的ID FOLDER_KNOWLEDGE_MAP = { r"/home/ll/test/file": "8d885deb-f653-4b44-9f0e-21ea4fe19584" } # 文件存储状态(保存已上传文件的信息,避免重复上传) uploaded_files = {} # 指定哈希文件的保存路径 PERSISTENCE_FILE = r"/home/ll/test/hashes.txt" # 替换为你的哈希文件保存路径 # 日志函数 def log(message, level="INFO"): print(f"[{level}] {message}") # 确保哈希文件存在 def ensure_persistence_file(): if not os.path.exists(PERSISTENCE_FILE): log(f"Hash file does not exist. Creating a new one at {PERSISTENCE_FILE}") open(PERSISTENCE_FILE, "w").close() # 加载已上传文件的哈希值 def load_uploaded_files(): log(f"Loading uploaded files from {PERSISTENCE_FILE}...") try: with open(PERSISTENCE_FILE, "r") as f: for line in f: line = line.strip() if line: try: file_path, checksum = line.split("|") uploaded_files[file_path] = checksum log(f"Loaded {file_path} with checksum {checksum}", level="DEBUG") except ValueError: log(f"Skipping invalid line in hash file: {line}", level="WARNING") except FileNotFoundError: log(f"Hash file {PERSISTENCE_FILE} not found. Starting with an empty hash list.", level="WARNING") # 保存已上传文件的哈希值 def save_uploaded_files(): log(f"Saving uploaded files to {PERSISTENCE_FILE}...") try: with open(PERSISTENCE_FILE, "w") as f: for file_path, checksum in uploaded_files.items(): f.write(f"{file_path}|{checksum}\n") log("Successfully saved uploaded files.") except Exception as e: log(f"Failed to save uploaded files: {e}", level="ERROR") # 上传文件到知识库 def upload_file(file_path, knowledge_id): headers = { 'Authorization': f'Bearer {TOKEN}', 'Accept': 'application/json' } log(f"Uploading {file_path} to knowledge {knowledge_id}") try: with open(file_path, 'rb') as file: checksum = hashlib.sha256(file.read()).hexdigest() if file_path in uploaded_files and uploaded_files[file_path] == checksum: log(f"File {file_path} has already been uploaded. Skipping.", level="DEBUG") return with open(file_path, 'rb') as file: response = requests.post( f'{API_BASE_URL}files/', headers=headers, files={'file': file}, timeout=200 ) if response.status_code == 200: file_id = response.json().get('id') add_file_to_knowledge(file_id, knowledge_id) uploaded_files[file_path] = checksum log(f"Successfully uploaded {file_path}") else: log(f"Error uploading {file_path}: {response.status_code} - {response.text}", level="ERROR") except requests.exceptions.RequestException as e: log(f"Failed to upload {file_path}: {e}", level="ERROR") # 将文件添加到知识库 def add_file_to_knowledge(file_id, knowledge_id): headers = { 'Authorization': f'Bearer {TOKEN}', 'Content-Type': 'application/json' } data = {'file_id': file_id} response = requests.post( f'{API_BASE_URL}knowledge/{knowledge_id}/file/add', headers=headers, json=data ) if response.status_code != 200: log(f"Error adding file {file_id} to knowledge {knowledge_id}: {response.status_code} - {response.text}", level="ERROR") # 文件系统事件处理器 class SyncHandler(FileSystemEventHandler): def __init__(self, source_folder, knowledge_id): self.source_folder = source_folder self.knowledge_id = knowledge_id def on_created(self, event): if not event.is_directory: file_path = event.src_path file_name = os.path.basename(file_path) if (os.path.exists(file_path) and os.path.getsize(file_path) > 0 and not file_name.startswith('~$') and not file_name.endswith('.tmp')): upload_file(file_path, self.knowledge_id) log(f"Detected new file: {file_path}") def on_modified(self, event): if not event.is_directory: file_path = event.src_path file_name = os.path.basename(file_path) if (os.path.exists(file_path) and os.path.getsize(file_path) > 0 and not file_name.startswith('~$') and not file_name.endswith('.tmp')): upload_file(file_path, self.knowledge_id) log(f"Detected modified file: {file_path}") def on_deleted(self, event): if not event.is_directory: file_path = event.src_path if file_path in uploaded_files: del uploaded_files[file_path] log(f"Deleted file {file_path} removed from uploaded_files list.") # 程序启动时进行增量同步 def initial_sync(folder, knowledge_id): log(f"Performing initial sync for folder {folder} with knowledge {knowledge_id}") for root, _, files in os.walk(folder): for file in files: file_path = os.path.join(root, file) if (os.path.exists(file_path) and os.path.getsize(file_path) > 0 and not file.startswith('~$') and not file.endswith('.tmp')): upload_file(file_path, knowledge_id) # 主函数 def main(): log("Starting file synchronization...") ensure_persistence_file() load_uploaded_files() observers = [] for folder, knowledge_id in FOLDER_KNOWLEDGE_MAP.items(): # Perform initial sync to handle any changes that occurred while the program was not running initial_sync(folder, knowledge_id) log(f"Setting up observer for folder {folder} with knowledge {knowledge_id}") observer = Observer() handler = SyncHandler(folder, knowledge_id) observer.schedule(handler, folder, recursive=True) observer.start() observers.append(observer) try: while True: time.sleep(1) except KeyboardInterrupt: log("Stopping synchronization...") save_uploaded_files() for observer in observers: observer.stop() for observer in observers: observer.join() if __name__ == "__main__": main()
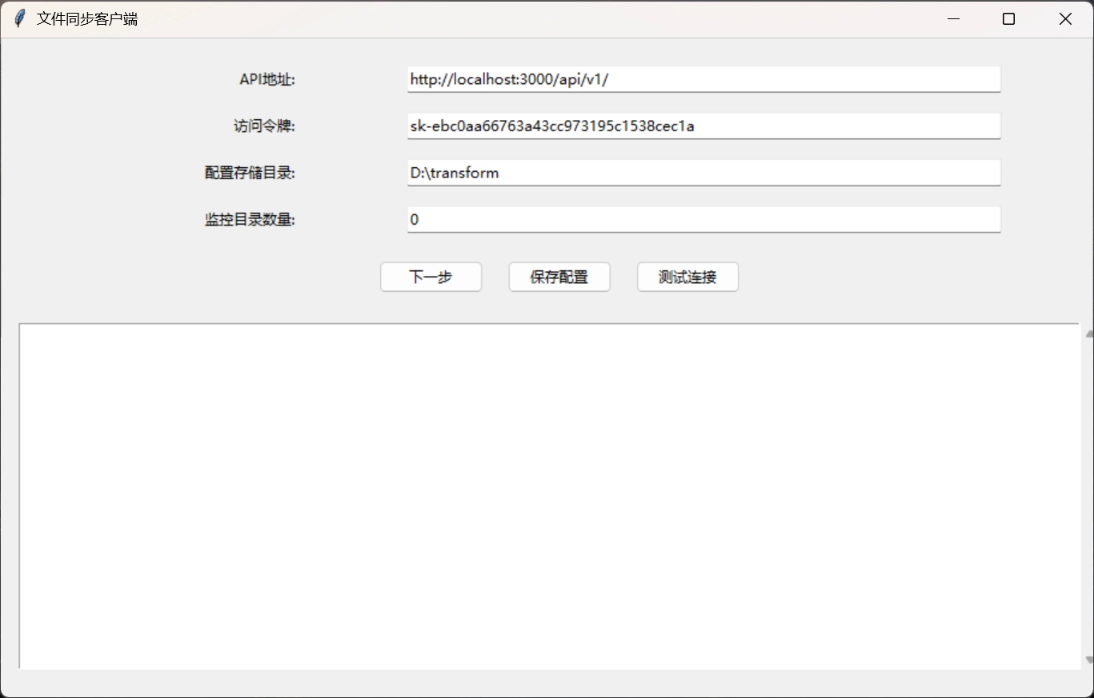
2.将另一个名为Sync-OpenWebUI的exe文件添加到Windows任务计划程序中,设置为开机延时2min启动(等待Open web UI启动以防出现bug),重启电脑查看任务管理器中这个程序进程是否正常,如果正常文件应该正常被转化和上传到知识库中。转化后的文件存在你设置的配置文件储存地址。中文文件夹被重命名为拼音简写。